Google’s new Lumiere text-to-video AI leverages an innovative Space-Time-U-Net (STUNet) framework for enhanced realism in rendering object motion seamlessly. As per Ars Technica, this diffusion model understands positioning of elements (space) and movement flow (time) within frames to generate sharper, flowing videos.
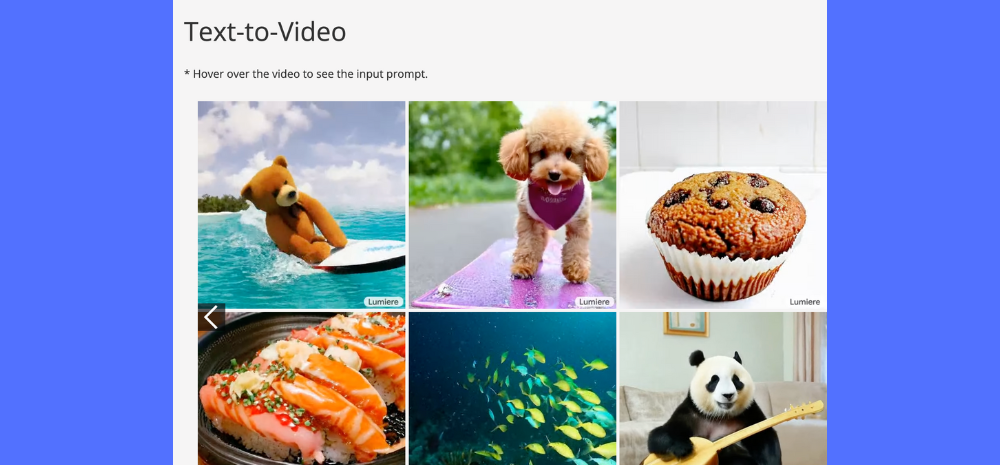
In comparisons, Lumiere produced 80 frames using STUNet versus just 25 frames by systems like Stable Diffusion that combine discrete image frames of pre-generated action. The pre-print research outputs showcase major leaps in natural motion synthesis.
Exponential Improvements Within Years
Remarking on the rapid progress, a text-focused reporter noted AI video generation has gone from disjointed imagery to near photo-realism within barely few years as pioneered by firms like Runway. Lumiere establishes Google as a credible contender against metaverse-geared offerings by Meta, Runway and others.
Testing suggests Lumiere creates more realistic motion flow and detail than predecessors, indicative of the vastly improved capabilities now being unlocked through newer architectures purpose-built for video. This is exceptionally fast evolution given where Google’s video AI stood merely 24 months back.
Multimodal Future Across Text, Images, Video
The video push aligns with Google increasingly pursuing a multimodal AI strategy – text and images via Gemini, video through Lumiere and so on. Integrations between these models can enable interactive visual storytelling, personalized media and immersive experiences at scale in future.
Though not launched yet, Lumiere already demonstrates state-of-the-art text-to-video prowess today. It validates sustained AI research excellence to push boundaries on expressive realism through pioneering techniques like STUNet over coming years.